TL;DR: Top 5 Takeaways
- Reasoning Powerhouse: QwQ from Alibaba’s Qwen team excels at math, coding, and analytical tasks with a human-like “think first” approach.
- Compact Efficiency: At 32 billion parameters, it rivals giants like DeepSeek-R1 (671B) with far less compute power.
- Open-Source Edge: Freely available under Apache 2.0, unlike proprietary models like OpenAI’s o1.
- Innovative Twist: Its self-reflective design and inference-time scaling could redefine AI problem-solving—if proven at scale.
- Unverified Hype: Claims of top scores (e.g., 90.6% MATH-500) lack independent audits, leaving its true potential a question mark.
Picture an AI that doesn’t just spit out answers but pauses to think, questions itself, and then nails a complex math problem or coding challenge. That’s QwQ, Alibaba’s latest brainchild, launched in November 2024 as a preview by the Qwen team. Dubbed “Qwen with Questions” (pronounced “quill”), this 32-billion-parameter model isn’t here to chat—it’s here to reason, and it’s making
QwQ Unveiled: What It Brings to the Table
QwQ is all about deep reasoning. It’s built to tackle tasks that demand step-by-step logic—think solving a high-school math Olympiad problem or debugging code for a live app [1]. Unlike chatty AI, it uses inference-time scaling: it “thinks” longer during processing, mimicking human reflection to boost accuracy [2]. A demo on qwenlm.github.io shows it adding parentheses to fix an equation, walking through its logic like a meticulous student [3]. With a 32,768-token context window, it can handle lengthy documents or codebases, making it a fit for technical heavy lifting [4].
The kicker? It’s open-source under Apache 2.0, downloadable on Hugging Face, and accessible via Qwen’s chatbot—though still in a “preview” phase with limited rollout [5]. Alibaba’s Qwen team gave it a two-phase training: first on math and coding precision, then on general reasoning, aiming for a brainy assistant that doesn’t just guess [6]. For your team, this could mean sharper data analysis or faster prototyping—if you can get past its early-stage quirks.
How QwQ Differs from the Pack
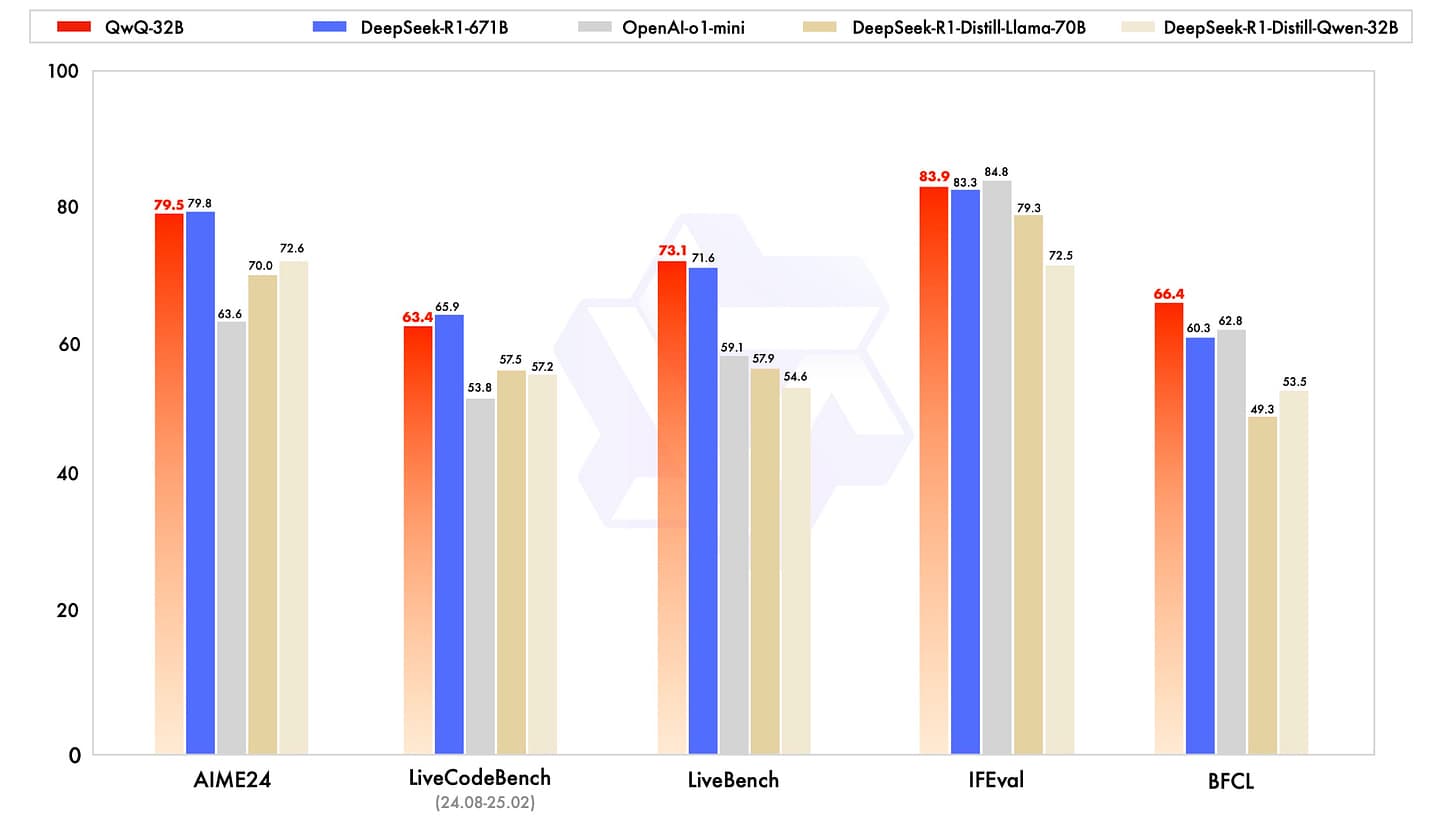
QwQ isn’t your typical AI. Compare it to ChatGPT or Claude—these shine at conversation but stumble on structured reasoning, often guessing at math or code [7]. QwQ methodically solves problems, scoring 50% on AIME (math Olympiad) where others flounder [8]. OpenAI’s o1, another reasoning star, is proprietary and bulkier; QwQ’s 32B parameters match or beat o1-mini’s benchmarks (e.g., 65.2% GPQA) while staying open and lean [9]. DeepSeek-R1, with its 671B parameters, flexes muscle but demands heavy compute—QwQ keeps up (90.6% MATH-500) with a fraction of the resources [10].
Unlike Manus, which executes real-world tasks like building websites, QwQ sticks to analytical turf—think less “doer,” more “thinker” [11]. And while AutoGPT needs tech chops to configure, QwQ is plug-and-play, though its preview limits broad testing [5]. It’s a specialist, not a generalist, and that focus sets it apart.
Why QwQ Feels Innovative
What makes QwQ stand out? First, its efficiency: matching DeepSeek-R1’s prowess with 20x fewer parameters is a feat of reinforcement learning magic [12]. Second, it’s self-reflective—QwQ questions its own assumptions, reducing errors in tricky tasks, a trick dubbed its “philosophical spirit” by Qwen [3]. Third, being open-source invites developers to tweak it, potentially sparking a wave of reasoning-focused tools [13]. Fourth, its inference-time scaling—thinking harder during runtime—flips the script on speed-obsessed AI, aiming for precision over haste [2].
For businesses, this could mean a lean, smart assistant for analytics or coding that doesn’t guzzle compute budgets. If QwQ scales, it might redefine how we build AI—less brawn, more brains.
The Proof Problem: Missing Data and Stats
Alibaba claims QwQ shines: 65.2% on GPQA (scientific reasoning), 50% on AIME, 90.6% on MATH-500, and 50% on LiveCodeBench (coding) [4]. Impressive, right? MATH-500’s 90.6% trounces many peers, and 50% on AIME beats o1-mini’s lower marks [9]. But here’s the snag: these stats are straight from Qwen’s mouth—no independent audits back them up [1]. GAIA, a real-world benchmark, lists H2O.ai at 65%, but QwQ’s scores aren’t on public leaderboards [14]. No raw data, no failure cases, no testing conditions—just Qwen’s blog and a demo [3].
Its preview status compounds this—access is tight, mostly via Hugging Face or Qwen’s chat, leaving most users in the dark [5]. X buzz (e.g., “matches DeepSeek-R1” [15]) fuels excitement, but without third-party eyes, it’s hype, not fact. Add quirks like language mixing or recursive loops, and the shine dims until proof arrives [4].
QwQ: A Brainy Bet Worth Watching
QwQ, Alibaba’s reasoning gem, is a bold swing at smarter, leaner AI. Its features—analytical muscle, compact design, open-source access—split it from chatbots and bulky rivals, offering a fresh take on problem-solving tech. Its innovations could shift AI toward efficiency and precision, a win for businesses craving sharp tools without the overhead. But with limited access and unverified claims, it’s a tantalizing “what if” for now. Keep QwQ on your radar—if Alibaba opens the gates and the stats hold, it might just outthink the competition.
Top 10 Reference Links
- Yahoo News SG, “Manus: Another DeepSeek Moment?”
- VentureBeat, “Alibaba’s QwQ Beats o1-Preview”
- Qwen Blog, “QwQ-32B-Preview”
- Hugging Face, “QwQ-32B-Preview”
- InfoQ, “QwQ-32B-Preview Unveiled”
- Alibaba Cloud, “QwQ Open-Source Release”
- OpenAI Blog, “ChatGPT Capabilities”
- CTOL Digital, “QwQ Narrows the Gap”
- eWeek, “Alibaba vs. OpenAI & DeepSeek”
- DataCamp, “Testing QwQ-32B”